Have you ever wished your Python libraries were faster? Could run on GPUs without changing your huge codebase, or switching to a different library, or rewriting everything in a faster language (C, Rust)? Discover how API dispatching mechanism redirects function calls to a FASTER implementation present in a separate backend package by various approaches like leveraging the Python's `entry_point` specification, Array API Standards in various Scientific Python projects!
In the first five minutes, we will familiarise ourselves with the concept of Dispatching in general with a demo using dummy libraries, and understand the problems of dispatching a function call. Then we will understand how this problem of slow performance arises in real-world with an example of NetworkX, a popular, pure Python library used for graph(aka network) analysis, with a quick demo of how the performance decreases with larger and larger graph datasets. Balancing this need for more efficient and faster algorithms with the core values of NetworkX-- to remain free from any external dependencies and to uphold its pure Python nature, led to the development of a new backend dispatching system in NetworkX.
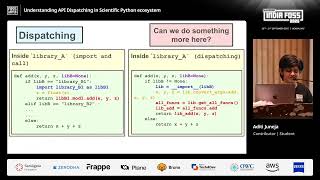
In the next 5-10 minutes, we will understand entry-point based API dispatching is in general, what are Python entry_points, how they are utilised to discover the backend packages and then redirect function calls to the faster backend implementations present in a separate backend package. We will explore all this using a simple and general(not specific to graph libraries) example(dummy) libraries. And then we will draw a parallel to how this dispatching mechanism is implemented in NetworkX and is being implemented in scikit-image.
Then in the next 5-10 minutes, we will understand how and when this API dispatching mechanism could be adopted by different scientific Python libraries, and go over the example of recent developments in scikit-image project and what were some of the challenges with dispatching array inputs(i.e. image inputs) and briefly over the Array API standards and how libraries like SciPy and Sklearn have adopted this Array API. I plan on expanding on all these with brief coding demo-s. Then we will go over some ecosystem wide initiatives for coordination and adoption of these dispatching mechanisms like SPEC-2 and `spatch`.
Then if time permits, we'll also go into the developments around the nx-parallel backend or the DataFrame API standards and some of the details of the features of the dispatching mechanism, like the usage of NETWORKX_TEST_BACKEND environment variable, the second entry_point for backend meta-data, the backend_priority, can_run, should_run etc. And a summary of other NetworkX backends and some future to-dos for NetworkX’s dispatching. Finally, concluding with an interactive Q&A.
---
Intended audience:
- Contributors/Maintainers of Python libraries who are interested in offering their users faster algorithms without changing their codebase and the user-API
- People who work with large graph, image, array datasets
- anyone interested in API dispatching, or any of the above stuff :)
Thank you :)
Some basic knowledge of Python is expected; should know what objects and classes are.
.png)